Control your Generative AI costs with the Vertex API’s context caching
Note: This blog has two authors.
What is context caching?
Vertex AI is a Google Cloud machine learning (ML) platform that, among other things, provides access to a collection of generative AI models. This includes the models known under the common name “Gemini models”. When you interact with these models you provide it with all the information about your inquiry. The Gemini models accept information in multiple formats including text, video and audio. The provided information is often referred to as “context”. The Gemini models are known to accept very long contexts.
Use of the Gemini models is not free. Pricing is defined by the length of the context. In June 2024, Vertex AI introduced context caching, a method allowing to reduce the cost of requests that contain repeat context with high input token counts. Like with many other features you have to evaluate pros and cons before using it. In this post we review a use case that calls the Gemini models with a very long context and analyzes advantages of using the context caching method.
Use case: source code changes recommendations
Our team at Google maintains a large number of source code repositories with codebase in different programming languages. It includes tracking and implementing reported issues such as bugs and feature requests. Some of these issues are small, well defined, and fairly easy to resolve. By “well defined” we consider issues that have a clear verbose description and by “easy to resolve” ‒ issues that likely have one unambiguous, evident solution. As an experiment, we wanted to use the Gemini model to recommend implementation for these issues.
Here’s an architecture diagram of the tool that we’ve been developing:
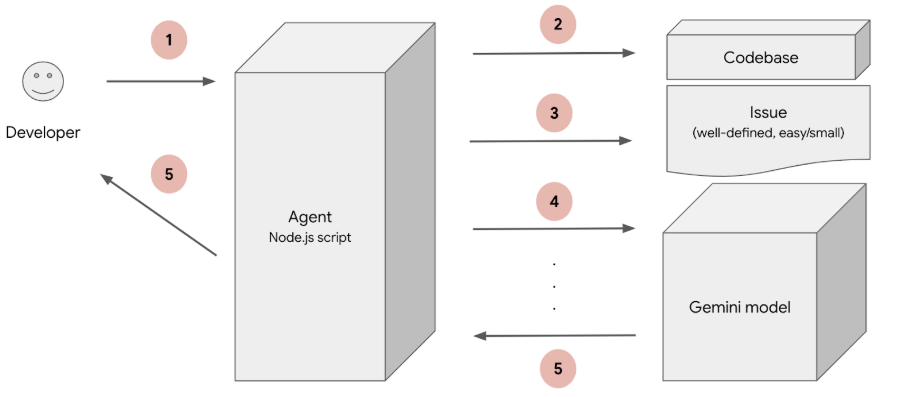
- The agent is called with information about the issue and the code repository where the issue is reported.
- The agent loads all source files from the repository.
- The agent loads the information about the issue from the repository.
- All the loaded information (source code files, and the issue details) is passed to the Gemini model, along with instructions asking to recommend code changes.
- The model responds with recommendations including the source code and instructions for resolving the issue.
We noticed that the source code that the agent loads in step 2, makes up the largest part of the whole information or context sent to the Gemini model. The repositories that we used in the experiment have more than 3000 lines of code and the size of the source code is larger than 100KB. The repository that was used for testing the tool had (at the moment of the experiment) size of 131KB. Since we process multiple issues per repository, we decided to try context caching and to cache the source code part of the context in order to improve the length of the context that we pass to the model in step 4.
Implementing context caching
To simplify access to Vertex AI API we used Google Cloud SDK @google-cloud/vertexai library. This is a JavaScript npm module. However, this library is available in other languages including Java, Python, Go, Ruby and more. Implementing the context caching using the Vertex AI client library is fairly simple. Please note that the interface of the client library is idiomatic to TypeScript that we used for our tool. Vertex AI client libraries in other programming languages may have different interfaces.
Create CachedContent
In our experiment we assumed that the source code of the repository does not change during the session that we generate recommendations for the repository’s issues.
Using this assumption we create a context cache of the repository’s source code at the beginning of the process (step 2).
The client library exposes a CachedContent interface that represents the cached context.
The naming can be misleading since it says “CachedContent” and not “CachedContext”.
Further we will continue using “context” to reference the information that is passed to the model.
A single instance of the CachedContent interface allows you to cache multiple types of the context information: text, video, and audio. Each instance of CachedContent requires a time-to-live (ttl) parameter which determines how long the cached context will be cached.
async function createCachedTextContent(
projectId: string,
location: string,
modelVersion: string,
content: string): Promise<CachedContent> {
const vertexAI = new VertexAI({ project: projectId, location: location });
const cachedContent: CachedContent = {
displayName: 'My cached content',
model: `projects/${projectId}/locations/${location}/publishers/google/models/${modelVersion}`,
systemInstruction: '',
contents: [
{ role: 'USER', parts: [{ text: content }] },
],
ttl: 3600 * 3 + 's', // 3 hours
}
const createdCachedContent = await vertexAI.preview.cachedContents.create(cachedContent);
if (!createdCachedContent) {
throw new Error('Failed to create CachedContent.');
}
return createdCachedContent;
}
The code snippet shows a function that creates and returns an instance of the CachedContent interface for a text content.
The function accepts the following arguments:
- Existing Google Cloud project ID with enabled Vertex AI API
- Google Cloud region as a location (see documentation for the list of all available regions)
- Valid Gemini model version (see documentation for the list of all available models and versions)
- Text content to be cached
See dataset format for more information about the contents field format and how to cache video and audio content.
We did not use system instructions in our experiment.
If you do, you can populate the systemInstructions field to cache system instructions as well.
Generate content with your CachedContent
When it is time to generate content, you will use a previously created CachedContent instance. A call to the Gemini model to generate recommendations using the cached context will look similar the one without cached context except for the following details:
- The name of the method you invoke will be
getGenerativeModelFromCachedContent()instead ofgetGenerativeModel(). - You will need an instance of the
CachedContentinterface. We kept theCachedContentinstance that is returned by thecreateCachedTextContent()function (see the code snippet above). The name uniquely identifies the cached context object managed for you by Vertex AI and looks likeprojects/PROJECT_ID/locations/LOCATION/cachedContents/CONTENT_ID.
See the code snippet below for an example of generating content using the CachedContent instance:
async function generateContent(
projectId: string,
location: string,
modelVersion: string,
cachedContent: CachedContent,
prompt: string): Promise<string | undefined> {
const vertexAI = new VertexAI({ project: projectId, location: location });
const modelFromCache = vertexAI.preview.getGenerativeModelFromCachedContent(
cachedContent,
{ model: modelVersion },
);
const result = await modelFromCache.generateContent({
contents: [{ role: 'USER', parts: [{ text: prompt }] }],
});
if (result && result.response && result.response.candidates && result.response.candidates[0]) {
return result.response.candidates[0].content.parts[0].text;
}
return undefined;
}
The function in the snippet accepts the following arguments:
- Existing Google Cloud project ID with enabled Vertex AI API
- Google Cloud region as a location (see documentation for the list of all available regions)
- Valid Gemini model version (see documentation for the list of all available models and versions)
- The previously created
CachedContentinstance - Prompt for the inference
Important
The cache is expected to be defined for the same model.
It is also highly recommended to Vertex AI to generate content in the same location where the cache has been created.
You may experience performance and other cost increases if you try to use the cached content from a different location.
The model will generate content based on the context that is composed from the system instructions, cached content and the prompt that is provided in the call: [system instructions] + [cached content] + [content in the call].
Discover existing CachedContent instances
In the code snippets above, we created a new instance of CachedContent and we used it in the call to the generateConten() function.
If your code is expected to use an already existing CachedContent instance, you can read the list of cached objects and find “your” object.
See the following code snippet that shows how it can be done:
const PROJECT_ID = 'your-project-id';
const LOCATION = 'us-central1';
const vertexAI = new VertexAI({ project: PROJECT_ID, location: LOCATION });
const cachedContentsResponse = await vertexAI.preview.cachedContents.list();
for (const cachedContent of cachedContentsResponse.cachedContents) {
// Your code to inspect an instance and save the found cachedContent object for further use
}
Was the use of context caching worth it?
In this experiment the tool was making just a couple of requests per hour and, as mentioned, the codebase size was 131KB large.
In this situation we did not see much improvement in performance or the costs of using the context caching. Let’s do some napkin math on how many requests and size of the context we need to make per hour in order to benefit from using the context caching.
We will use the Generative AI on Vertex AI pricing from Nov 5, 2024 and the Gemini 1.5 Flash model.
By the time you read this blog post, pricing and the Gemini models may change.
We will assume the size of the repeated context is 131KB (the same as in our experiment) and the size of the context that changes in each request is 1KB.
Using N to annotate a number of requests to Vertex AI API made in an hour we get the following cost to call the model without caching the context:
Here, $0.0000375 is a price of 1k characters input for context with the total size >128K.
The cost to call the mode using cached context will be:
\[ \begin{aligned} Cost_{cached} = 0.000009375 + 0.00025 + 1 *0.00001875* N \approx \frac{0.0000375}{2}*(906 + N) = 0.00003752* (453 + \frac{N}{2}) \end{aligned} \]Here, \(131 *0.000009375 + 0.00025\) calculates the cost for caching 131K characters input for 1 hour. $0.000009375 is the price of caching 1K characters of cached input for context of the size >128K. And $0.00025 is a storage price of 1K characters for 1 hour. If we do not refresh the context after 1 hour, the cost of caching for the following hour will be lower. \(0.00001875* N\) is the price of N calls made for the 1k characters input for context of the total size <128K. All prices in these calculations are for the Gemini 1.5 Flash model.
This way the calls using cached context will be cheaper than non-cached call if and only if: \(132 * N > 453 + \frac{N}{2}\).
It is easy to see that in our experiment the cost of using context caching will be lower with N ≥ 4 requests per hour. Note that using the Gemini models is not expensive. When the context size is small you would not need to consider techniques like the context caching in the first place. However, it is worth checking that pricing did not change when you started your development.
Is context caching right for you?
As we showed, it is good to do quick calculations to figure out whether the context caching use decreases cost in your use case. Here are some factors that you will have to consider:
- Context length: The larger the context you can cache, the larger the savings you get.
- Minimum context length: At the time we wrote this blog post (November 2024), the minimum size of a context cache is 32,769 tokens. For the context of UTF-8 characters one token is approximately 4 characters, making the minimal number of characters that can be cached ≥130,000.
- Context rate of change: How quickly will the context that you cached be outdated? The longer you can use it without updating, the better. A great example is a video clip or a fixed set of articles and documents. In our experiment, the cached context consisted of a continuously changing codebase, we had to engineer a way to cache files that are less likely to be modified in the near future and to figure out how to refresh the cached context when the codebase changes.
- Requests per hour: How many requests to the Gemini model do you plan to make during an hour? The more requests, the more bang-for-your-buck. A good example would be an AI chat agent with a large, cached context (system instructions) that’s used by many users, such as an AI assistant on a popular website. In such scenario, you may even choose to only cache your AI chat agent’s context during high-traffic hours.

