Control What You Log
DISCLAIMER: This post is not about log storage billing or managing log sinks.
Have you ever read or heard the phrase “Write everything to logs”? This is good advice. You never know what information can be useful or when. It is easy to do in Google Cloud. With help of audit logs all infrastructure, security and other cloud internal events are stored in Cloud Logging. And you can write application logs by simply printing them to stdout. However, there are situations when you may need to prevent some log entries from being stored:
- You enabled VPC flow logs in your network project to analyse traffic with a third party network packet scanner and see how your log storage and your bill goes up daily
- You consolidated all logs in your organization in the single project and see that you have 2x log entries stored than expected
- You implemented log de-identification for your application logs and you discover that original log entries are still being stored in your project
In these and other situations you need to exclude log entries from being stored.
You can control what log entries are stored using log sinks. The exact method depends on your goal. Let’s review these methods.
Project-level exclusions
Every log sink resource has the exclusions field that is a list of uniquely named filters that the sink applies to every log entry passing through it.
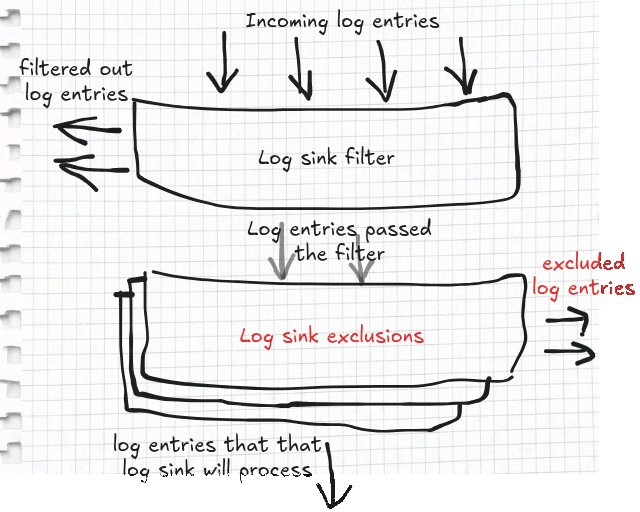
Where to define the exclusions? Log storage is represented by the size of log buckets.
So, the only log sinks that you should configure with exclusions are those that route log entries to log buckets.
Every project has two system-defined log sinks: _Required that is responsible for storing critical audit logs (they are stored free of charge) and _Default that is responsible for storing all other logs ingested to this project.
“System-defined” means that these log sinks (and underlying log buckets) are automatically provisioned when a project is created.
Note
The log buckets these sinks route incoming log entries to have the same names as the sinks which often cause confusion. Be mindful not to mix between them.
The _Required log sink is read-only and cannot be modified while the _Default log sink allows changes of its exclusions field.
Unless you define another log sink(s) that routes log entries to some log buckets, the _Default log sink is one that you edit to exclude logs from being stored.
Taking an example of enabling VPC flow logs from before, let’s see how you can exclude these logs from being stored.
According to documentation, VPC flow logs have one of the following log IDs:
- “compute.googleapis.com/vpc_flows” log collects log entries for subnets
- “networkmanagement.googleapis.com/vpc_flows” log collects all other VPC flow logs including VPC networks, some subnets logs, and VLAN attachments for Cloud Interconnect, and Cloud VPN tunnels
How to define the exclusions? To define a filter for the exclusion you need to use the log filter expression for building queries. For this case you need to create a filter that matches logs with the above log IDs. The filter expression will be:
log_id("compute.googleapis.com/vpc_flows") OR log_id("networkmanagement.googleapis.com/vpc_flows")
Tip
Before applying an exclusion filter, always paste the filter logic into the Logs Explorer query bar. This allows you to preview which logs will be matched and prevent the accidental exclusion of critical operational or security logs.
The gcloud command that updates the log sink’s exclusions will look like this:
gcloud logging sinks update _Default \
--project=${PROJECT_ID} \
--add-exclusion=name='vpc_flow_exclusion',\
filter='log_id("compute.googleapis.com/vpc_flows") OR log_id("networkmanagement.googleapis.com/vpc_flows")'
This command configures the _Default log sink on the project with ID_ _${PROJECT_ID} to exclude VPC flow logs from being stored in the project’s log bucket.
If you use Terraform you can do the same operation using the following configuration:
import {
id = "projects/{{var.project_id}}/sinks/_Default"
to = google_logging_project_sink.default
}
resource "google_logging_project_sink" "default" {
name = "_Default"
destination = "logging.googleapis.com/projects/{{var.project_id}}/locations/global/buckets/_Default"
exclusions {
name = "vpc_flow_exclusion"
filter = "log_id(\"compute.googleapis.com/vpc_flows\") OR log_id(\"networkmanagement.googleapis.com/vpc_flows\")"
}
}
Another example of using exclusions is keeping logs that you perceive as not needed from being stored. For example, you can exclude Google Cloud Load Balancer health check logs using the following filter expression:
resource.type="http_load_balancer" AND httpRequest.userAgent="GoogleHC/1.0"
If in doubt whether to exclude logs or not, remember the advice in the beginning of this post: Write everything to logs.
Disable project-level logs
When you are certain that no logs that are ingested to a project need to be stored, you can disable storing all logs together (except for the critical audit logs).
In that case, instead of defining exclusions you can simply disable the _Default log sink:
gcloud logging sinks update _Default --disabled \
--project=${PROJECT_ID}
To set it up using Terraform configuration, you will need to set the disabled argument of the google_logging_project_sink resource to “true”:
import {
id = "projects/{{var.project_id}}/sinks/_Default"
to = google_logging_project_sink.default
}
resource "google_logging_project_sink" "default" {
name = "_Default"
destination = "logging.googleapis.com/projects/{{var.project_id}}/locations/global/buckets/_Default"
disabled = true
}
Be careful when you do this because it disables storing any non-critical audit logs (e.g. data access audit logs) as well as any application logs in your project. This method is useful when you export all your logs to a third party and do not want to store duplicated logs in the cloud.
Cross-organization exclusions
The previous two methods work on logs that are stored in a project.
In situations when log aggregation is implemented at organizational level these methods will not work well.
This is impractical to change the _Default log sink configuration of every project in the organization.
In this situation the recommended method is to use intercepting log sinks.
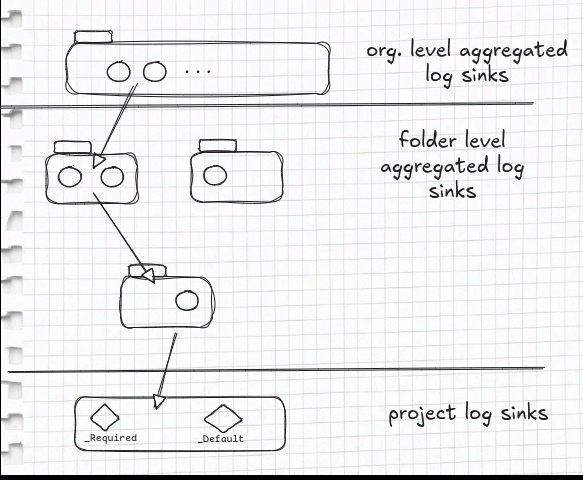
This type of log sinks can be defined only at organizational or folder levels.
To implement aggregation you already have to have aggregated log sinks at least in one folder or at organizational level.
Aggregated sinks are applied not only at the resource level they are defined (i.e. organization or folder) but also at all underlying levels.
In other words, an aggregated sink will route logs in all underlying projects.
The aggregated sinks are applied according to levels.
First the sinks that are defined in the organization.
Then the topmost folder.
Then the folder under it and so it goes on down to the project level (regular) log sink.
To prevent logs from being stored, the aggregated log sink can be configured to be an intercepting aggregated log sink. If one of the aggregated log sinks at the first level of folders is converted to be intercepting, it effectively stops the underlying aggregated log sinks as well as project’s log sinks to be applied.
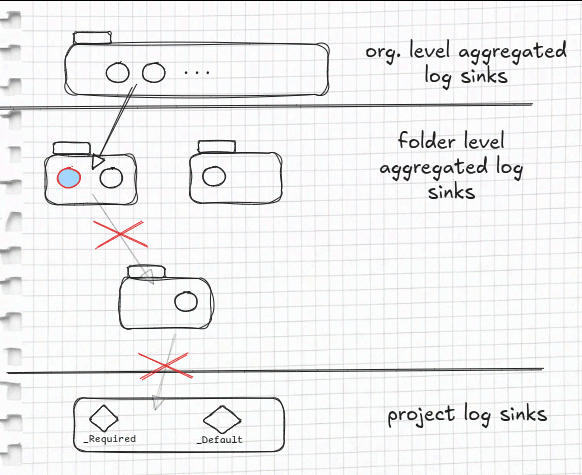
Note
Another aggregated log sink(s) in the same folder with the intercepting sink are applied regardless.
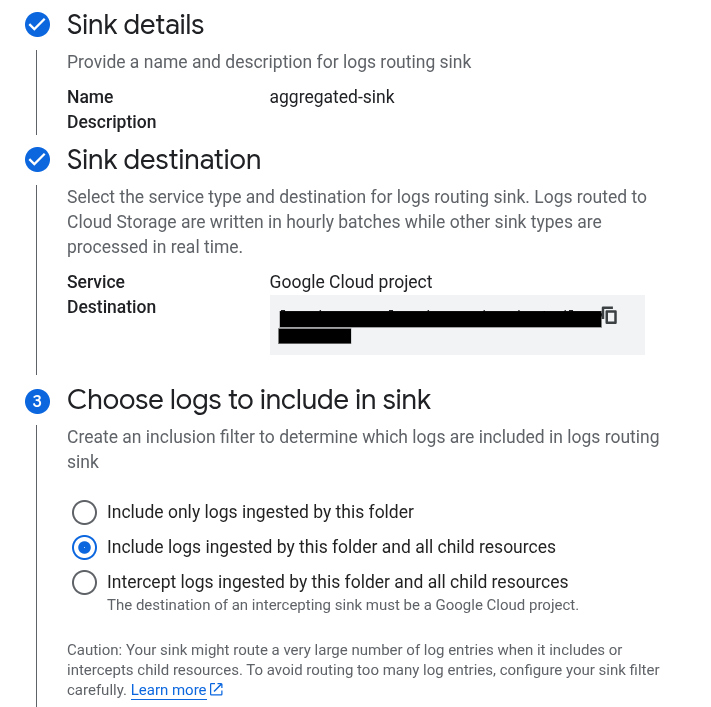
Not any aggregated log sink can be configured to be an intercepting sink. This configuration is only available for the aggregated sinks whose destination is a Google Cloud project. Because log aggregation architecture usually routes all logs to a designated project this requirement is easily fulfilled. You can change aggregated sink’s configuration in the console by selecting “Intercept logs ingested by this folder and all child resources”:
You also can do it using CLI or with Terraform.
For a folder ${FOLDER_ID} and a sink ${SINK_NAME} the command will be:
gcloud logging sinks update ${SINK_NAME} --intercept-children \
--folder=${FOLDER_ID}
To run this command for a sink at organization’s level, using --organization parameter instead.
Google provider for Terraform provides google_logging_organization_sink and google_logging_folder_sink to manage log sinks at organization and folder levels respectively.
The following example modifies an aggregated sink at folder level assuming there are folder_id and sink_name input variables:
import {
id = "folders/{{var.folder_id}}/sinks/{{var.sink_name}}"
to = google_logging_folder_sink.aggregated_sink
}
resource "google_logging_folder_sink" "aggregated_sink" {
name = var.sink_name
destination = "logging.googleapis.com/folders/{{var.folder_id}}/locations/global/buckets/{{var.sink_name}}"
intercept_children = true
}
Wrapping up
You have full control of what logs you store.
Logs have a great value and may greatly decrease your troubleshooting time.
This post covers three primary methods for controlling log storage: adding exclusion filters to the _Default sink, disabling the sink entirely, and intercepting log sinks for cross-organizational control.
Unless you have serious reasons like cost optimization or security concerns, consider storing all your logs.
This post does not look into the costs of logging storage. You can further review billing data analysis guidelines to find recommendations for cost optimizations.
If you want to learn more about logging in Google Cloud see the following resources:
