How Export Google Cloud Logs
Google Cloud provides efficient and not expensive storage for application and infrastructure logs. Logs stored in Google Cloud can be queried and analyzed using the analytical power of BigQuery. However, there are scenarios when Google Cloud customers may need to export log data from Google Cloud to third party (3P) solutions. This post reviews two main use cases of log exporting: exporting already stored logs and exporting logs while they are being ingested. The post focuses on how to configure and implement the part of the exporting process that handles extracting logs from Google Cloud. The part of loading the data into 3P solutions is not explored because of the variety of requirements and constraints that different 3P solutions expose.
Export stored logs
Google Cloud uses log buckets to store logs. Each project has default log buckets and users can create additional log buckets in the project when needed.
Note
Log buckets are not the same as Cloud Storage buckets.
There are several methods to retrieve log data stored in log buckets:
Directly read logs using entries.list Logging API. You can read log entries in your project by defining a filter expression using Logging query language. The following example shows how to download all log entries that were stored in 2024 year:
Using gcloud CLI command:
> gcloud logging read 'timestamp>="2024-01-01T00:00:00Z" AND \
timestamp<="2024-12-31T23:59:59Z"' > 2024_logs.jsonl
And using Google Cloud SDK library in Python:
import google.cloud.logging
client = google.cloud.logging.Client()
filter_str = f'timestamp>="2024-01-01T00:00:00Z" AND timestamp<="2024-12-31T23:59:59Z"'
for entry in client.list_entries(filter_=filter_str):
# process entry
The API lets you define a list of projects or log buckets (as a list of resources) and a filter expression and retrieves log entries matching this expression from all listed resources. When using this method, be aware of existing quotas and limits of Logging API such as 60 calls per minute limit. You can optimize your calls to this API following these best practices:
- Increase your API quota limits. For more information, see Quota adjuster.
- Set a large pageSize parameter to minimize the total number of API calls needed to read the data
- Set up request’s timeout long enough to allow sufficiently large deadline to complete querying all log entries
- Retry quota errors with exponential backoff
Note that these improvements do not help if you need to retrieve logs from more than 100 different projects or log buckets.
Copy to a Storage bucket and read from there. The entries.list Logging API is not intended for high-volume retrieval of log entries. You can copy log entries from the log bucket to Cloud Storage buckets and then leverage 3P integration Google Cloud or run your own code that reads from Storage buckets and sends logs to 3P. To do this you will need to provide a Storage bucket and a filter expression (see the previous paragraph for more information). Here is an example of copying project logs ingested in 2024 into an already existing Storage bucket using gcloud CLI command:
> gcloud logging copy _Default ${BUCKET_NAME} \
--location=global \
log-filter='timestamp>="2024-01-01T00:00:00Z" AND \
timestamp<="2024-12-31T23:59:59Z"'
Consult with documentation about permissions required to run the “logging copy” command. This method benefits from unlimited read rate of objects from Cloud Storage. 3P solutions such as Splunk and Sumo Logic provide integrations that monitor a Storage bucket for new files and read the discovered files. See this example for downloading objects from a bucket using code. It is also possible to download all objects from a bucket for one time export operation.
Leverage Log Analytics to query logs intended for export using SQL and BigQuery tools. This requires upgrading the log bucket to use Log Analytics. For more information about steps required to upgrade log buckets, see Configure log buckets. This method is mentioned as an alternative to exporting logs. Using this method you can provide access to logs to third-party BI, analytics, or security platforms that support native BigQuery integration.
There are two possible scenarios for exporting stored logs: one-time export of a particular set of logs or a recurrent export of logs based on some periodic schedule. While a one-time export is straightforward: run your CLI commands in a shell or create a Cloud Run job to run your code. The recurrent export requires some set up in order to trigger the process. The following diagram shows a recommended architecture to be used with any of the above three methods.
[diagram: show use of scheduler with cloud build or cloud run or cloud function to trigger execution]
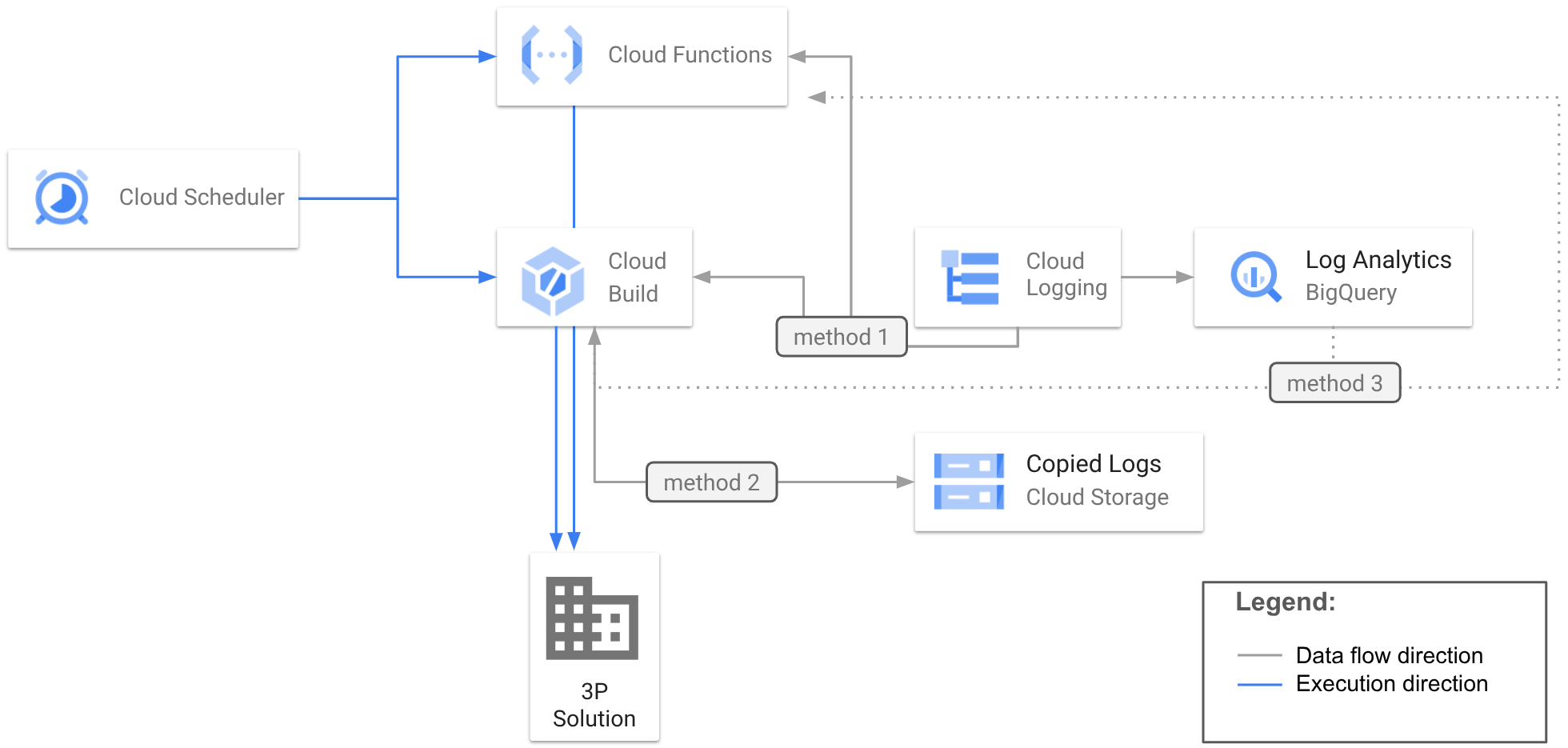
The diagram shows running each of the 3 methods using scheduled Cloud Build script and scheduled Cloud Run Job or scheduled Cloud Run Function.
Export logs when they are being ingested
This use case is more frequent for Google Cloud customers who often maintain centralized log management across multiple platforms using one of available 3P solutions. The main difference between this case and export of the stored logs is an ability to route incoming logs to PubSub or Cloud Storage using the Cloud Logging router. The process of configuring log routing is straightforward.
1) Create a resource where your router will stream incoming logs. To create a new storage bucket you can use the gcloud storage buckets create CLI command, google_storage_bucket Terraform resource or write a code. Similarly, to create a new PubSub topic you can use gcloud pubsub topics create CLI command, google_pubsub_topic Terraform resource or implement it in code.
2) Create a log sink pointing to the destination: a Storage bucket or a PubSub topic. Like with creating a destination, you can do it using gcloud command, google_logging_project_sink Terraform resource or write a code. The sink configuration requires a filter expression that is very similar to one that was used in the first use case. You should not use the timestamp field in the expression since the incoming logs are all fresh and expect to have the current date/time for the timestamp or not to have this field set up.
3) Grant permissions to the created sink to write logs to the destination. If you run the gcloud CLI command, the output of the command will instruct you how to do it. The following example shows commands required to grant log sink necessary permissions to route logs to Cloud Storage and to PubSub. First, get the sink’s writer identity using the following command:
> WRITER_ID=$(gcloud logging sinks describe ${SINK_NAME} \
--format='value(writerIdentity)')
Then grant a required role to the acquired writer identity to access Cloud Storage:
> gcloud storage buckets add-iam-policy-binding ${BUCKET_NAME} \
--member="${WRITER_ID}" --role='roles/storage.objectCreator'
Or PubSub:
> gcloud pubsub topics add-iam-policy-binding ${TOPIC_ID} \
--member="${WRITER_ID}" --role='roles/pubsub.publisher'
See this Terraform example that shows how to do the same in Terraform.
Completing these three steps results in all incoming logs that match the filter to be routed to the defined destination.
Note
Routing does not prevent logs from being stored in Cloud Logging. To exclude logs from being stored in Cloud Logging you will need to configure the _Default log sink.
If your 3P solution supports integration with Cloud Storage or PubSub the log sink configuration is all that you need to complete the export. The following paragraphs review the methods to execute code that calls 3P API to proactively write the logs that were streamed to Cloud Storage or to PubSub.
Export logs streamed to Cloud Storage
This method is recommended for use cases where batch processing is acceptable and high reliability is paramount. Since many 3P solutions support ingesting files from Cloud Storage, this pattern decouples your export process from the third-party tool’s availability. If you decide to implement export logic in your code, you will need to create an Eventarc event trigger for Cloud Run service that will invoke your code where you will have to analyse which objects were added or updated in Cloud Storage. Once the objects are identified, you can use the same logic of downloading object like in the section describing the export of stored logs. And then to call the 3P API to store the exported log data.
Export logs streamed to PubSub
This is a recommended way to export logs. PubSub is a resilient service that can scale according to changing volume and size of the incoming logs. There are several ways to run your implementation of writing logs to a 3P solution:
a. Implement ETL pipeline using Dataflow. This method is best fit for export tasks that process a high volume of logs and involve multiple and complex data transformations before the 3P API can be called. For example, consider exporting logs generated by EMR (Electronic Medical Record) application of a large hospital. The export process has to be reliable and resilient to failures. It also needs format conversions and obfuscation of medical and personal information before they can be stored at 3P. which will aggregate the stream into batches and will call 3P API to export the batches of logs to 3P. You can see an example of using PubSub and Dataflow pipeline to export logs to Datadog. b. Use Eventarc triggers to run a Cloud Run Function to process PubSub messages. This method is recommended when you expect a sparse low volume stream of logs. The function will be called on each log entry separately making the processing of a high volume of logs slow and infrastructure overhead. If the implementation of exporting logs to 3P is complex and does not fit into a function format, you can configure a trigger to call a Cloud Run service instead.
Wrapping up
What method of exporting logs to choose depends on several factors including:
- When you need to export logs: logs that are stored in Cloud Logging or new incoming logs
- Volume of the exporting logs: staggering log frequency and volume of incoming logs or continues low volume frequency
- Available integrations of the selected 3P solution with Google Cloud
- Need for log transformations during the export
See the following decision tree to find the method that is best suited for your task:
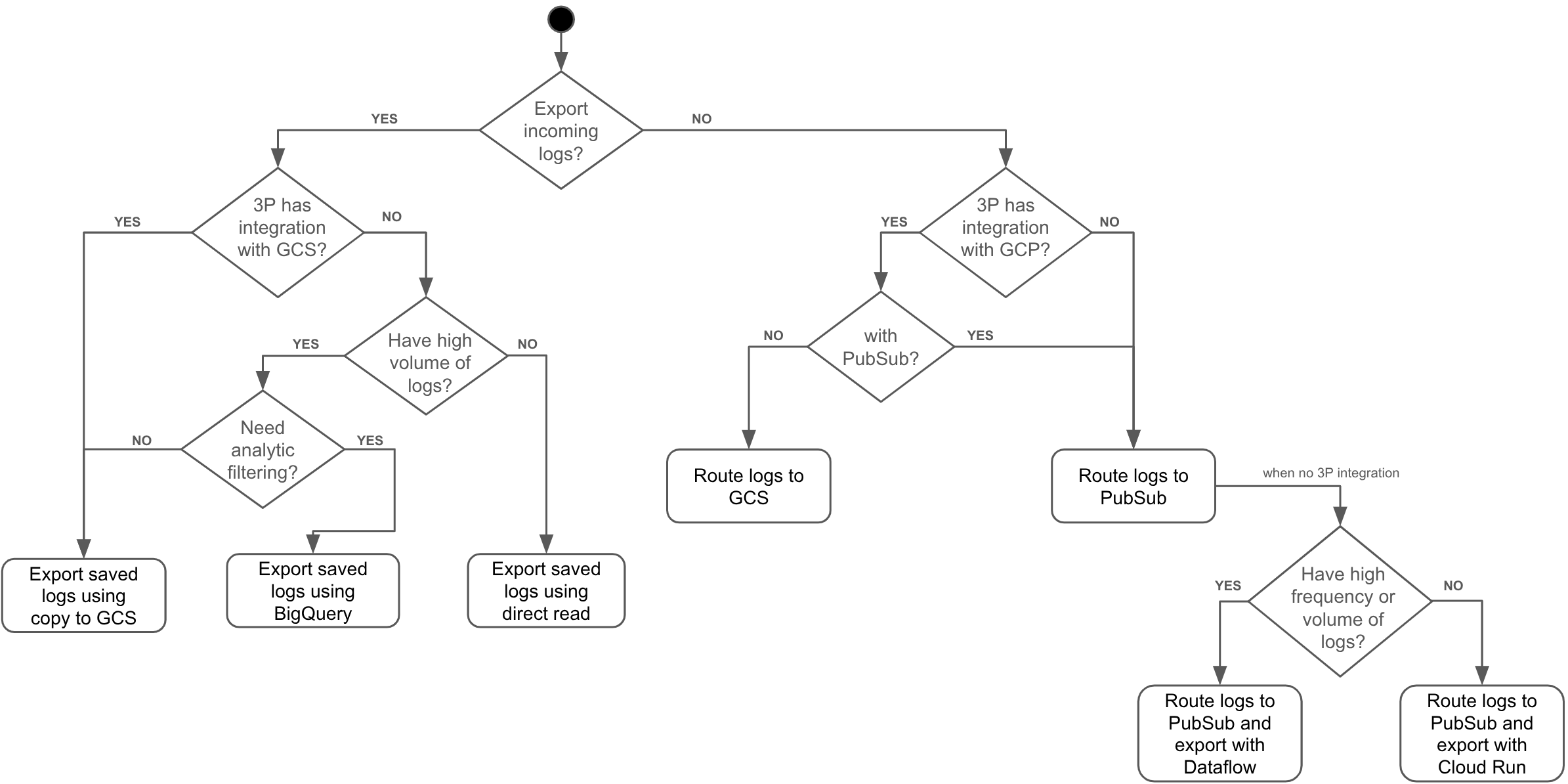
Beyond the technical implementation, always consider the practical aspects of your export pipeline. Evaluate the cost implications of your chosen destination (e.g., GCS storage costs vs. Pub/Sub operational costs) and processing service (e.g., Dataflow vs. Cloud Run). For sensitive data, explore security enhancements like using VPC Service Controls to prevent data exfiltration and support of Customer-Managed Encryption Keys (CMEK) to your destination resources.
The described methods can be used for other operations on logs. Review the following materials to learn more:
