All the ways to scrape Prometheus metrics in Google Cloud
Production systems are being monitored for reliability and performance tracking to say the least. Monitored metrics ‒ a set of measurements that are related to a specific attribute of a system being monitored, are first captured in the executing code of the system and then are ingested to the monitoring backend. The selection of the backend often dictates the methods(s) of ingestion. If you run your workloads on Google Cloud and use self-managed Prometheus server and metric collection, this post will help you to reduce maintenance overhead and some billing costs by utilizing Google Cloud Managed Service for Prometheus for collecting and storing Prometheus metrics.
Prometheus is a common choice for collecting, storing and managing the monitored metrics. In Prometheus terms, a scrape is the action of collecting metrics through an HTTP request from a targeted system, parsing the response, and ingesting the collected samples to storage. Product systems running on Google Cloud can bring along their “own” self-managed Prometheus service with all the scrape setup and invest in maintaining infrastructure and configurations or can benefit from Google Cloud Managed Service for Prometheus and the extended support for scraping operations. You can read more about Google’s managed Prometheus service or Managed Service for Prometheus in documentation. Let’s have a look at each of the scraping options that you get with Managed Service for Prometheus.
Scraping Prometheus metrics from a Virtual Machine
If you run a workload of virtual machines (aka GCE instances) that expose endpoints for scraping, all you need is Ops Agent. The agent has the designated Prometheus receiver configuration that enables you to configure scraping for each workload including possible pre-processing of metric’s labels. Before you decide to use the Prometheus receiver, determine if there is already an Ops Agent integration for the application you are using. For information on the existing integrations with the Ops Agent, see Monitoring third-party applications. If there is an existing integration, we recommend using it.
For example, the following configures Ops Agent with a Prometheus receiver that scrape metrics at
endpoint localhost:7979/probe each 30 seconds:
metrics:
receivers:
prometheus:
type: prometheus
config:
scrape_configs:
- job_name: 'json_exporter'
scrape_interval: 30s
metrics_path: /probe
params:
agent: ['ops_agent']
static_configs:
- targets: ['localhost:7979']
Scraping Prometheus metrics on GKE
To scrape metrics emitted by an application in GKE, the cluster has to have the enabled managed
Prometheus service.
This service is enabled by default for any new Auto-pilot or started GKE cluster.
For existing clusters you can enable the service in Cloud Console by checking the “Enable
Managed Service for Prometheus” option in the Operations section of the “Create a Kubernetes
cluster” wizard.
This section is found under Advanced Settings when creating an Auto-pilot cluster or under Features
when creating a standard cluster.
Or you can use the --enable-managed-prometheus option in the
gcloud container clusters update command.
Under the hood enabling this service installs the Managed Service for Prometheus operator.
Look at instructions for installing the Managed Service for Prometheus operator
on a non-GKE cluster for more information.
Once the Managed Service for Prometheus operator is enabled, all that is left is to deploy PodMonitoring
resource configuration.
The example below defines a PodMonitoring resource that uses a
Kubernetes label selector to find all pods in the NAMESPACE_NAME namespace
that have the label app.kubernetes.io/name with the value my-service.
The matching pods are scraped on port 7979, every 30 seconds, on the /probe HTTP path.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: metric-collector-example
namespace: NAMESPACE_NAME
spec:
selector:
matchLabels:
app.kubernetes.io/name: my-service
endpoints:
- port: 7979
interval: 30s
path: /probe
Another way to scrape Prometheus metrics from GKE workloads is to use an OTel collector. This method is more generic and has advantages over the Managed Service for Prometheus operator when you run workloads that emit metrics in multiple formats. However, running OTel collector comes at extra costs including maintaining overhead to deploy and manage the collector and additional capacities for performant metric collection and ingestion.
Cloud Run: scrape with side-car
Services that run on Cloud Run need some extra work to scrape their Prometheus metrics. First, they have to add (or update) their deployment configuration to add a side-car container to the main (ingress) container of the Cloud Run service.
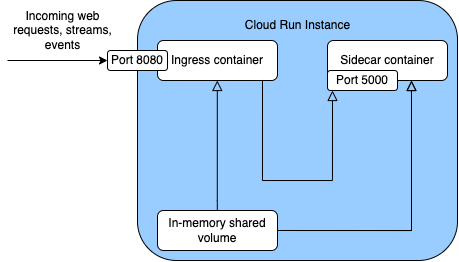
There are multiple ways to deploy a Cloud Run service with a side-car container: using Cloud Console, CLI or using service manifest. All of them require that the ingress container image of the service is built before the service is deployed. If you use continuous deployment or Cloud Build to build the ingress container image for your service, you will need to do modifications to your deployment pipeline. The following shows the use of the service manifest because it uses the serveless manifest and provides maximum customization.
The manifest below deploys the user’s application my-service from the container image
REPOSITORY.URL/CONTAINER/IMAGE and uses default configuration of the RunMonitoring resource.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: my-cloud-run-service
spec:
template:
metadata:
annotations:
run.googleapis.com/execution-environment: gen2
run.googleapis.com/container-dependencies: '{"gmp-collector-sidecar":["my-service"]}'
spec:
containers:
- image: REPOSITORY.URL/CONTAINER/IMAGE
name: my-service
ports:
- containerPort: 8000
- image: 'us-docker.pkg.dev/cloud-ops-agents-artifacts/cloud-run-gmp-sidecar/cloud-run-gmp-sidecar:1.1.1'
name: gmp-collector
The RunMonitoring resource uses existing PodMonitoring options to support Cloud Run while
eliminating some options that are specific to Kubernetes.
The default configuration is described by the following manifest:
apiVersion: monitoring.googleapis.com/v1beta
kind: RunMonitoring
metadata:
name: run-gmp-sidecar
spec:
endpoints:
- port: 8080
path: /metrics
interval: 30s
It scrapes the ingress container on port 8080, every 30 seconds, on the /metrics HTTP path.
If you need to customize these settings you need to follow the documentation
to create a volume where the configuration can be stored and extend the side container
gmp-collector with the following changes marked with +:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: my-cloud-run-service
spec:
template:
# metadata declaration...
spec:
containers:
# ingress container declaration...
- image: 'us-docker.pkg.dev/cloud-ops-agents-artifacts/cloud-run-gmp-sidecar/cloud-run-gmp-sidecar:1.1.1'
name: gmp-collector
+ volumeMounts:
+ - mountPath: /etc/rungmp/
+ name: monitoring-config
+ volumes:
+ - name: monitoring-config
# rest of the volume declaration...
There are several methods to mount custom configuration of the RunMonitoring resource.
The documentation recommends using the Security Manager but it seems simpler
and more reasonable to store the configuration in Cloud Storage as described in this blog.
You can reference Cloud Run documentation about configuring Cloud Storage volume mounts.
Wrapping up
Systems that emit monitoring data in Prometheus format do not require sophisticated DevOps work to
have their metrics scraped in Google Cloud.
Using managed solutions gives a care-free way to collect metrics from workloads running on VMs,
GKE clusters or Cloud Run.
If you are interested in a more technical, hands-on review of the particular solution, please let
know using the feedback form or in the comments to this post.
You can find more information about Google Managed Service for Prometheus in the following sources:
- Managed Service for Prometheus documentation
- Google Cloud Community forum about Prometheus
- Ops Agent configurations for Prometheus metrics
- Other Ops Agent metric exports to use as alternative to Prometheus receiver
- Troubleshooting Managed Service for Prometheus
- How to ingest Prometheus self-monitoring metrics from Managed Service for Prometheus
- Use Managed Service for Prometheus outside of Google Cloud
- Manifests used in the Managed Service for Prometheus documentation
